Stating the Problem#
Once properly stated, a problem can be formulated as an objective function to be solved on a D‑Wave solver. The example in the Introduction chapter states a communication-networks problem as the well-known graph problem, vertex cover.
D‑Wave provides several resource containing many reference examples:
Ocean software’s collection of code examples on GitHub.
D-Wave papers (for example, [dwave2]) and links to user applications.
For beginners, Ocean software documentation provides a series of code examples, for different levels of experience, that explain various aspects of quantum computing in solving problems.
This chapter provides a sample of problems in various fields, and the available resources for each (at the time of writing); having a relevant reference problem may enable you to use similar solution steps when solving your own problems on D‑Wave solvers.
Many of these are discrete optimization, also known as combinatorial optimization, which is the optimization of an objective function defined over a set of discrete values such as Booleans.
Keep in mind that there are different ways to model a given problem; for example, a constraint satisfaction problem (CSP) can have various domains, variables, and constraints. Model selection can affect solution performance, so it may be useful to consider various approaches.
Problem |
Beginner Content Available? |
Solvers |
Content |
|---|---|---|---|
QPU, hybrid |
Code, papers |
||
QPU |
Papers |
||
QPU |
Papers |
||
Yes |
QPU |
Code, papers |
|
QPU, hybrid |
Papers |
||
Yes |
QPU, hybrid |
Code, papers |
|
QPU |
Papers |
||
Yes |
QPU, hybrid |
Code, paper |
|
QPU |
Papers |
||
Yes |
QPU, hybrid |
Code, papers |
|
QPU, hybrid |
Papers |
Whether or not you see a relevant problem here, it’s recommended you check out the examples in D‑Wave’s collection of code examples and corporate website for the latest examples of problems from all fields of study and industry.
Circuits & Fault Diagnosis#
Fault diagnosis attempts to quickly localize failures as soon as they are detected in systems such as sensor networks, process monitoring, and safety monitoring. Circuit fault diagnosis attempts to identify failed gates during manufacturing, under the assumption that gate failure is rare enough that the minimum number of gates failing is the most likely cause of the detected problem.
The Example Reformulation: Circuit Fault Diagnosis section in the Reformulating a Problem chapter shows the steps of solving a circuit fault diagnosis problem on a D‑Wave QPU.
Code Examples#
-
Solves a logic circuit problem using Ocean tools to demonstrate solving a CSP on a D‑Wave QPU solver.
-
Demonstrates the use of D‑Wave solvers to solve a three-bit multiplier circuit.
-
Verifies equivalence of two representations of electronic circuits using a discrete quadratic model (DQM).
Papers#
[Bia2016] discusses embedding fault diagnosis CSPs on the D‑Wave system.
[Bis2017] discusses a problem of diagnosing faults in an electrical power-distribution system.
[Pap1976] discusses decomposing complex systems for the problem of generating tests for digital-faults detection.
[Per2015] maps fault diagnosis to a QUBO and embeds onto a QPU.
Computer Vision#
Computer vision develops techniques to enable computers to analyse digital images, including video. The field has applications in industrial manufacturing, healthcare, navigation, miltary, and many other areas.
Papers#
[Arr2022] compares quantum and classical approaches to motion segmentation.
[Bir2021] discusses a quantum algorithm for solving a synchronization problem, specifically permutation synchronization, a non-convex optimization problem in discrete variables.
[Gol2019] derive an algorithm for correspondence problems on point sets.
[Li2020] translates detection scores from bounding boxes and overlap ratio between pairs of bounding boxes into QUBOs for removing redundant object detections.
[Ngu2019] demonstrates good prediction performance of a regression algorithm for a lattice quantum chromodynamics simulation data using a D‑Wave 2000Q™ system.
Database Queries (SAT Filters)#
A satisfiability (SAT) filter is a small data structure that enables fast querying over a huge dataset by allowing for false positives (but not false negatives).
Papers#
Factoring#
The factoring problem is to decompose a number into its factors. There is no known method to quickly factor large integers—the complexity of this problem has made it the basis of public-key cryptography algorithms.
Code Examples#
-
Demonstrates the use of D‑Wave QPU solvers to solve a small factoring problem.
-
Demonstrates the use of D‑Wave QPU solvers to solve a small factoring problem.
Papers#
[Dri2017] investigates prime factorization using quantum annealing and computational algebraic geometry, specifically Grobner bases.
[Dwave3] discusses integer factoring in the context of using the D‑Wave Anneal Offsets feature; see also the Anneal Offsets section.
[Bur2002] discusses factoring as optimization.
[Jia2018] develops a framework to convert an arbitrary integer factorization problem to an executable Ising model.
[Lin2021] applies deep reinforcement learning to configure adiabatic quantum computing on prime factoring problems.
Finance#
Portfolio optimization is the problem of optimizing the allocation of a budget to a set of financial assets.
Papers#
[Coh2020] investigates the use of quantum computers for building an optimal portfolio.
[Coh2020b] analyzes 3,171 US common stocks to create an efficient portfolio.
[Das2019] provides a quantum annealing algorithm in QUBO form for a dynamic asset allocation problem using expected shortfall constraint.
[Din2019] seeks the optimal configuration of a supply chain’s infrastructures and facilities based on customer demand.
[Els2017] discusses using Markowitz’s optimization of the financial portfolio selection problem on the D‑Wave system.
[Gra2021] uses portfolio optimization as a case study by which to benchmark quantum annealing controls.
[Kal2019] explores how commercially available quantum hardware and algorithms can solve real world problems in finance.
[Mug2020] implements dynamic portfolio optimization on quantum and quantum-inspired algorithms and compare with D‑Wave hybrid solvers.
[Mug2021] proposes a hybrid quantum-classical algorithm for dynamic portfolio optimization with minimal holding period.
[Oru2019] looks at forecasting financial crashes.
[Pal2021] implement in a simple way some complex real-life constraints on the portfolio optimization problem
[Phi2021] selects a set of assets for investment such that the total risk is minimised, a minimum return is realised and a budget constraint is met.
[Ros2016a] discusses solving a portfolio optimization problem on the D‑Wave system.
[Ven2019] investigates a hybrid quantum-classical solution method to the mean-variance portfolio optimization problems.
Graph Partitioning#
Graph partition is the problem of reducing a graph into mutually exclusive sets of nodes.
Code Examples#
-
Solves a graph partitioning problem on a QPU.
-
Solves a graph partitioning problem using the DQM solver in the Leap service.
-
Solves a maximum cut problem on a QPU.
-
Identifies clusters in a data set.
-
Fragments a population into separate groups via a “separator” using the DQM solver in the Leap service.
Papers#
[Bod1994] investigates the complexity of the maximum cut problem.
[Gue2018] performs simulations of the Quantum Approximate Optimization Algorithm (QAOA) for maximum cut problems.
[Hig2022] computes core-periphery partition for an undirected network formulated as a QUBO problem.
[Jas2019] proposes a using quantum annealing on extreme clustering problems.
[Ush2017] discusses unconstrained graph partitioning as community clustering.
[Zah2019] proposes an algorithm to detect multiple communities in a signed graph.
Machine Learning#
Artificial intelligence (AI) is transforming the world. You see it every day at home, at work, when shopping, when socializing, and even when driving a car. Machine learning algorithms operate by constructing a model with parameters that can be learned from a large amount of example input so that the trained model can make predictions about unseen data.
Most of the transformation that AI has brought to-date has been based on deterministic machine learning models such as feed-forward neural networks. The real world, however, is nondeterministic and filled with uncertainty. Probabilistic models explicitly handle this uncertainty by accounting for gaps in our knowledge and errors in data sources.
A probability distribution is a mathematical function that assigns a probability value to an event. Depending on the nature of the underlying event, this function can be defined for a continuous event (e.g., a normal distribution) or a discrete event (e.g., a Bernoulli distribution). In probabilistic models, probability distributions represent the unobserved quantities in a model (including noise effects) and how they relate to the data. The distribution of the data is approximated based on a finite set of samples. The model infers from the observed data, and learning occurs as it transforms the prior distributions, defined before observing the data, into posterior distributions, defined afterward. If the training process is successful, the learned distribution resembles the actual distribution of the data to the extent that the model can make correct predictions about unseen situations—correctly interpreting a previously unseen handwritten digit, for example.
In short, probabilistic modeling is a practical approach for designing machines that:
Learn from noisy and unlabeled data
Define confidence levels in predictions
Allow decision making in the absence of complete information
Infer missing data and latent correlations in data
Machine learning algorithms operate by constructing a model with parameters that can be learned from a large amount of example input so that the trained model can make predictions about unseen data.
Boltzmann Distribution#
A Boltzmann distribution is an energy-based discrete distribution that defines probability, \(p\), for each of the states in a binary vector.
Assume \(\vc{x}\) represents a set of \(N\) binary random variables. Conceptually, the space of \(\vc{x}\) corresponds to binary representations of all numbers from 0 to \(2^N - 1\). You can represent it as a column vector, \(\vc{x}^T = [x_1, x_2, \dots, x_N]\), where \(x_n \in \{0, 1\}\) is the state of the \(n^{th}\) binary random variable in \(\vc{x}\).
The Boltzmann distribution defines a probability for each possible state that \(\vc{x}\) can take using[1]
where \(E(\vc{x};\theta)\) is an energy function parameterized by \(\theta\), which contains the biases, and
is the normalizing coefficient, also known as the partition function, that ensures that \(p(\vc{x})\) sums to 1 over all the possible states of \(x\); that is,
Note that because of the negative sign for energy, \(E\), the states with high probability correspond to states with low energy.
The energy function \(E(\vc{x};\theta)\) can be represented as a QUBO: the linear coefficients bias the probability of individual binary variables in \(\vc{x}\) and the quadratic coefficients represent the correlation weights between the elements of \(\vc{x}\). The D‑Wave architecture, which natively processes information through the Ising/QUBO models (linear coefficients are represented by qubit biases and quadratic coefficients by coupler strengths), can help discrete energy-based machine learning.
Sampling from the D‑Wave QPU#
Sampling from energy-based distributions is a computationally intensive task that is an excellent match for the way that the D‑Wave system solves problems; that is, by seeking low-energy states. Samples from the D‑Wave QPU can be obtained quickly and provide an advantage over sampling from classical distributions.
When training a probabilistic model, you need a well-characterized distribution; otherwise, it is difficult to calculate gradients and you have no guarantee of convergence. While both classical Boltzmann and quantum Boltzmann distributions are well characterized, all but the smallest problems solved by the QPU should undergo postprocessing to bring them closer to a Boltzmann distribution; for example, by running a low-treewidth postprocessing algorithm.
Temperature Effects#
As in statistical mechanics, \(\beta\) represents inverse temperature: \(1/(k_B T)\), where \(T\) is the thermodynamic temperature in kelvin and \(k_B\) is Boltzmann’s constant.
The D‑Wave QPU operates at cryogenic temperatures, nominally \(15\) mK, which can be translated to a scale parameter \(\beta\). The effective value of \(\beta\) varies from QPU to QPU and in fact from problem to problem since the D‑Wave QPU samples are not Boltzmann and time-varying phenomena may affect samples. Therefore, to attain Boltzmann samples, run the Gibbs chain for a number of iterations starting from quantum computer samples. The objective is to further anneal the samples to the correct temperature of interest \(T = 1/{\beta}\), where \(\beta = 1.0\).
In the D‑Wave software, postprocessing refines the returned solutions to target a Boltzmann distribution characterized by \(\beta\), which is represented by a floating point number without units. When choosing a value for \(\beta\), be aware that lower values result in samples less constrained to the lowest energy states. For more information on \(\beta\) and how it is used in the sampling postprocessing algorithm, see the QPU Solver Datasheet guide.
Probabilistic Sampling: RBM
A restricted Boltzmann machine (RBM) is a special type of Boltzmann machine with a symmetrical bipartite structure; see Figure 40.
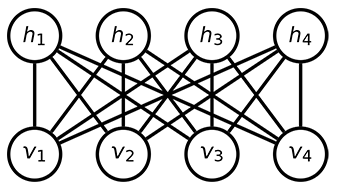
Fig. 40 Bipartite structure of an RBM, with a layer of visible variables connected to a layer of hidden variables.#
It defines a probability distribution over a set of binary variables that are divided into visible (input), \(\vc{v}\), and hidden, \(\vc{h}\), variables, which are analogous to the retina and brain, respectively.[2] The hidden variables allow for more complex dependencies among visible variables and are often used to learn a stochastic generative model over a set of inputs. All visible variables connect to all hidden variables, but no variables in the same layer are linked. This limited connectivity makes inference and therefore learning easier because the RBM takes only a single step to reach thermal equilibrium if you clamp the visible variables to particular binary states.
During the learning process, each visible variable is responsible for a feature from an item in the dataset to be learned. For example, images from the famous MNIST dataset of handwritten digits[3] have 784 pixels, so the RBMs that are training from this dataset require 784 visible variables. Each variable has a bias and each connection between variables has a weight. These values determine the energy of the output.
Without the introduction of hidden variables, the energy function \(E(\vc{x})\) by itself is not sufficiently flexible to give good models. You can write \(\vc{x}=[\vc{v},\vc{h}]\) and denote the energy function as \(E(\vc{v},\vc{h})\).
Then,
\begin{equation} p(\vc{x};\theta) = p(\vc{v},\vc{h};\theta) \end{equation}and of interest is
\begin{equation} p(\vc{v};\theta) = \sum_\vc{h} p(\vc{v},\vc{h};\theta), \end{equation}which you can obtain by marginalizing over the hidden variables, \(\vc{h}\).
A standard training criterion used to determine the energy function is to maximize the log likelihood (LL) of the training data—or, equivalently, to minimize the negative log likelihood (NLL) of the data. Training data is repetitively fed to the model and corresponding improvements made to the model.
When training a model, you are given \(D\) training (visible) examples \(\vc{v}^{(1)}, ..., \vc{v}^{(D)}\), and would like to find a setting for \(\theta\) under which this data is highly likely. Note that \(n^{th}\) component of the \(d^{th}\) training example is \(v_n^{(d)}\).
To find \(\theta\), maximize the likelihood of the training data:
The likelihood is \(L(\theta) = \prod_{d=1}^D p(v^{(d)};\theta)\)
It is more convenient, computationally, to maximize the log likelihood:
\begin{equation} LL(\theta)=log(L(\theta))=\sum_{d=1}^D {\log}p(v^{(d)};\theta). \end{equation}You can use the gradient descent method to minimize the \(NLL(\theta)\):
Starting at an initial guess for \(\theta\) (say, all zero values), calculate the gradient (the direction of fastest improvement) and then take a step in that direction.
Iterate by taking the gradient at the new point and moving downhill again.
To calculate the gradient at a particular \(\theta\), evaluate some expected values: \(E_{p(\vc{x};\theta)} f(\vc{x})\) for a set of functions \(f(\vc{x})\) known as the sufficient statistics. The expected values cannot be determined exactly, because you cannot sum over all \(2^N\) configurations; therefore, approximate by only summing over the most probable configurations, which you can obtain by sampling from the distribution given by the current \(\theta\).
Energy-Based Models
Machine learning with energy-based models (EBMs) minimizes an objective function by lowering scalar energy for configurations of variables that best represent dependencies for probabilistic and nonprobabilistic models.
For an RBM as a generative model, for example, where the gradient needed to maximize log-likelihood of data is intractable (due to the partition function for the energy objective function), instead of using the standard Gibbs’s sampling, use samples from the D‑Wave system. The training will have steps like these: a. Initialize variables. b. Teach visible nodes with training samples. c. Sample from the D‑Wave system. d. Update and repeat as needed.
Support Vector Machines
Support vector machines (SVM) find a hyperplane separating data into classes with maximized margin to each class; structured support vector machines (SSVM) assume structure in the output labels; for example, a beach in a picture increases the chance the picture is of a sunset.
Boosting
In machine learning, boosting methods are used to combine a set of simple, “weak” predictors in such a way as to produce a more powerful, “strong” predictor.
Code Examples#
Qboost is an example of formulating boosting as an optimization problem for solution on a QPU.
Papers#
General machine learning and sampling:
[Bia2010] discusses using quantum annealing for machine learning applications in two modes of operation: zero-temperature for optimization and finite-temperature for sampling.
[Ben2017] discusses sampling on the D‑Wave system.
[Inc2022] presents a QUBO formulation of the Graph Edit Distance problem and uses quantum annealing and variational quantum algorithms on it.
[Muc2022] proposes and evaluates a feature-selection algorithm based on QUBOs.
[Per2022] presents a systematic literature review of 2017–21 published papers to identify, analyze and classify different algorithms used in quantum machine learning and their applications.
[Vah2017] discusses label noise in neural networks.
RBMs:
[Ada2015] describes implementing an RBM on the D‑Wave system to generate samples for estimating model expectations of deep neural networks.
[Dum2013] discusses implementing an RBM using physical computation.
[Hin2012] is a tutorial on training RBMs.
[Kor2016] benchmarks quantum hardware on Boltzmann machines.
[Mac2018] discusses mutual information and renormalization group using RBMs.
[Rol2016] describes discrete variational autoencoders.
[Sal2007] describes RBMs used to model tabular data, such as users’ ratings of movies.
[Vin2019] describes using D‑Wave quantum annealers as Boltzmann samplers to perform quantum-assisted, end-to-end training of QVAE.
Energy-Based Models:
[Lec2006] describes EBMs.
Support Vector Machines:
[Boy2007] gives a concise introduction to subgradient methods.
[Wil2019] gives a method to train SVMs on a D‑Wave 2000Q system, and applies it to data from biology experiments.
Boosting:
[Nev2012] describes the Qboost formulation.
Map Coloring#
Map coloring is an example of a constraint satisfaction problem (CSP). CSPs require that all a problem’s variables be assigned values, out of a finite domain, that result in the satisfying of all constraints. The map-coloring CSP is to assign a color to each region of a map such that any two regions sharing a border have different colors.
The Example Reformulation: Map Coloring section in the Reformulating a Problem chapter is an example of map coloring on the D‑Wave system.
Code Examples#
-
Demonstrates an out-of-the-box use of a hybrid sampler solving a problem of arbitrary structure and size.
Map Coloring: Hybrid DQM Sampler
Demonstrates the hybrid discrete quadratic model (DQM) solver available in the Leap service.
-
Demonstrates solving a map-coloring CSP on a QPU.
-
Demonstrates the use of D‑Wave QPU solvers to solve a map-coloring problem.
Papers#
[Dwave4] describes solving a map coloring problem on a QPU.
Material Simulation#
One promise of quantum computing lies in harnessing programmable quantum devices for practical applications such as efficient simulation of quantum materials and condensed matter systems; for example, simulation of geometrically frustrated magnets in which topological phenomena can emerge from competition between quantum and thermal fluctuations.
Protein folding refers to the way protein chains structure themselves in the context of providing some biological function. Although their constituent amino acids enable multiple configurations, proteins rarely misfold (such proteins are a cause of disease) because the standard configuration has lower energy and so is more stable.
Papers#
[Kin2021] report on experimental observations of equilibration in simulation of geometrically frustrated magnets.
[Mni2021] reduces the molecular Hamiltonian matrix in Slater determinant basis to determine the lowest energy cluster.
[Per2012] discusses using the D‑Wave system to find the lowest-energy configuration for a folded protein.
[Tep2021] uses a quantum-classical solver to calculate excited electronic states of molecular systems. Note that the paper uses the qbsolv package, which has since been discontinued in favor of the hybrid solvers available in the Leap service and the dwave-hybrid package.
Scheduling#
The well-known job-shop schedule problem is to maximize priority or minimize schedule length (known as a makespan, the time interval between starting the first job and finishing the last) of multiple jobs done on several machines, where a job is an ordered sequence of tasks performed on particular machines, with constraints that a machine executes one task at a time and must complete started tasks.
Code Examples#
-
Shows new users how to formulate a constraint satisfaction problem (CSP) using Ocean tools and solve it on a D‑Wave QPU solver.
-
An implementation of [Ven2015] for D‑Wave QPU solvers.
-
A formulation of a discrete quadratic model (DQM) for solution using the hybrid DQM solver in the Leap service.
-
An implementation of [Ike2019] that forms a QUBO for solution by the hybrid BQM solver in the Leap service.
Papers#
[Ike2019] describes an implementation of nurse scheduling.
[Kur2020] describes an implementation of job-shop scheduling on a D‑Wave QPU solver.
[Liu2020] proposes to use deep reinforcement learning on job-shop scheduling.
[Ven2015] describes an implementation of job-shop scheduling on the D‑Wave system, which includes formulating the problem, translating to QUBO, and applying variable reduction techniques. It also talks about direct embedding of local constraints.
Traffic Flow#
One form of the traffic-flow optimization problem is to minimize the travel time of a group of vehicles from their sources to destinations by minimizing congestion on the roads being used.